Learning machine learning with python is a gratifying endeavor, and one of the most frequently misstepped technical learning journeys. Many tutorials on the internet claim to teach you machine learning over a weekend, and the lure of running a model through a high-level library without understanding the underpinning logic is all too easy. However, only those practitioners who establish their foundations solidly are able to build durable, valuable careers in machine learning. This roadmap is constructed to help you attain that.
Contents
- 1 Why Python is the Best First Language
- 1.1 Stage One: Proficiency in Python (Weeks 1–4)
- 1.2 Stage Two: Data manipulation with Pandas and Numpy (Weeks 5-8)
- 1.3 Stage Three: Statistics and mathematics for ML (Weeks 9-13)
- 1.4 Stage Four: Core Machine Learning With Scikit-learn (Weeks 14–22)
- 1.5 Stage Five: Deep Learning (Weeks 23–32)
- 1.6 Stage Six: Development of Genuine Projects and Portfolios
Why Python is the Best First Language
In 2026, Python will be the primary coding language for machine learning. Its simple and easy-to-read syntax, along with the well-developed ML ecosystem of scikit-learn, TensorFlow, PyTorch, Pandas, and NumPy, along with a huge community (> 1 million subscribers on Google Groups) make it the most popular choice. Additionally, almost all resources, guides, tutorial, and implementations of research papers that are in production ML systems. This makes it extremely difficult to learn ML in another language before Python.
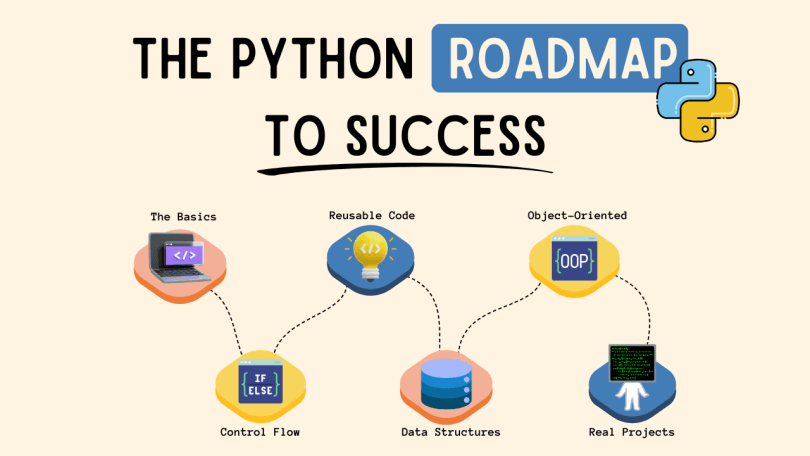
Stage One: Proficiency in Python (Weeks 1–4)
Working with ML (machine learning) requires proficient Python programming. It is not enough to know the basic scripting and syntax (i.e. knowing how to make Python run some code). One must also be proficient in understanding and applying concepts such as functions, classes, and modules; error and exception handling; list comprehension; and generators, as well as demonstrate the ability to efficiently make use of the standard library. In our context, there are two Python-related competencies of particular importance when it comes to working with ML.
These are: 1) Understanding how NumPy works, at the level of knowing and being able to use such concepts as; shapes, types, broadcasting, and vectorized operations. This is very important, given that just about every ML library accepts and operates on data that is represented as and organized into arrays, and 2) Developing the ability to read, as opposed to relying on the tutorials in the documentation, which is a skill that will be needed a lot when undertaking advanced ML. Early in ML development, especially with primitive or initial stages of it, and with developing analysis, it is beneficial to first learn the Jupyter Notebook method. This involves using separate cells to write code and document their findings. This will be more beneficial to the code’s development and analysis process than relying on Python modules or scripts. This is more or less the standard in ML development and Jupyter Notebooks will be something with which students will be working a lot.
Stage Two: Data manipulation with Pandas and Numpy (Weeks 5-8)
Machine learning models learn from data. But before training the models, the data needs to be loaded, cleaned, explored, and structured in a manner that the models can comprehend. For this, the main tool used is Pandas. For true mastery over Pandas, one must learn how to perform data manipulation effectively and efficiently, in addition to learning how to perform the specific manipulative task. This will create the Pandas foundation that is to be built upon. Preparing data for ML with Pandas includes: loading data from various formats; managing missing data via imputation or deletion; encoding non-numerical data; normalizing, or scaling, numerical data; merging and reshaping data sets; and finally, conducting exploratory data analysis to determine distributions, correlations, and anomalies. NumPy is the core library for data manipulation and modern ML. Familiarity with Numpy helps to build the foundation for data manipulation, from representation of data as multidimensional arrays to understanding the mental models used in manipulation of model inputs and outputs.
Stage Three: Statistics and mathematics for ML (Weeks 9-13)
This is the stage that defines the ML beginners and practitioners. Skipping this stage produces a ceiling of how advanced the ML knowledge can go. Bayes’ theorem, hypothesis testing, and confidence intervals are foundational statistics elements that evoke uncertainty, while expected value shows risk. To appreciate which prediction a model makes or the level of certainty a model has, these elements are vital. The fundamentals of the discipline include the vectors, matrices, and matrix multiplications; the dot and eigen value and vector products. The geometric interpretation of neural networks, principal component analysis, and the support vector machine operations require knowledge of these concepts. An understanding of most modern machine-learning models training process relies on the optimization method of most models, which is gradient descent, and that understanding is rooted in the calculus branch of derivatives and chain rule. While in practical training a model, one is not expected to derive gradients manually, one is expected to understand that the training of a model is centered on the equalities.
Stage Four: Core Machine Learning With Scikit-learn (Weeks 14–22)
With the mathematical foundations and data manipulation completed, we can finally reach the machine-learning stage, which is exactly how it was intended: viewing it as a toolbox for addressing clearly defined, well-established problems. Supervised learning involves algorithms that learn from training data that has been labeled in order to make forecasts on new instances. Core tools in supervised learning include linear regression for continuous prediction, logistic regression for binary classification, decision trees and random forests for interpretable models, gradient boosting for better predictive performance, and support vector machines for certain geometric classification concerns. Learning a single algorithm involves way more than learning a single function call. The algorithm may make certain assumptions about the data. How does the algorithm fail and what will it mean if those assumptions are violated? What are the hyper-parameters that control how this algorithm behaves and how are they tuned?
These are the questions that provide a true understanding of ML. The focus of unsupervised learning is on algorithms that identify structure in data that has not been labeled. The most commonly used methods for identifying groups are K-means clustering, DBSCAN for density-based clustering, and PCA for their dimensionality reduction. The skills that ensure that one does not make the mistake of being too fixated on the training performance of an algorithm and being too relaxed on performance in the wild are model evaluation and validation. The methodologies of cross validation, bias-variance trade-off, and the models used for testing, along with their evaluation performance, are paramount to the model’s performance. One of the most important aspects of machine learning is feature engineering, or the design of raw data representations that improve learning. This is often where the most significant performance gains come from. With enough experience, analysts learn the various ways to encode categorical variables, identify and process outliers, determine the appropriate data scaling methods for particular ML algorithms, and develop and process the data into features that convey the most important aspects of that data.
Stage Five: Deep Learning (Weeks 23–32)
Neural network-based deep learning creates the most advanced machine learning systems from 2026 and utilizes computer vision, natural language processing, and speech recognition, and generative models. With the knowledge gained from previous stages, deep learning builds upon that to solve problems that existing algorithms solve inadequately. For learners starting deep learning in 2026, the most appropriate choice is PyTorch. Dynamic computation graphs, and pythonic interfaces make it the most transferable investment and with the most previous deep learning research being conducted in PyTorch. Production environments might also be utilizing it. Before working with any higher-level abstractions, learners must have a solid understanding of the fundamental principles of deep learning: the architecture of neural networks, various activation functions, the concepts of forward and backward propagation, and the associated loss functions, optimization algorithms, and regularization methods, including understanding the differences between convolutional and recurrent networks.
Stage Six: Development of Genuine Projects and Portfolios
The last step prior to obtaining a job is to create three to five authentic machine learning projects that illustrate a complete machine learning pipeline. This includes data preparation, modeling, evaluation, and communication of results. Obtaining a dataset of a real-world complex problem that is publicly available (such as a tabular prediction problem, an image classification problem, or a text analysis problem) and documenting all of the analytical thought processes and model versions, will generate enough portfolio material to augment your lack of preparation for a technical interview. The machine learning using python roadmap is long and challenging. Each step is built upon the last, and those practitioners who complete the roadmap will achieve real proficiency, as opposed to the surface level acquaintance that prevents most self-directed learners from realizing their aspirations.





